# Assertion Processing
Last updated 2018-12-13
# Overview
This page describes:
- How Assertions (claims of competency made on behalf of an “entity”) are stored in CaSS
- How third-party applications query CaSS to determine competencies held by an entity
- How CaSS responds to such queries
- How CaSS can be used as a more traditional “profile manager.”
- How CaSS implements the ADL Total Learning Architecture “profile API.”
This page describes the procedure CaSS currently uses to answer a query about a person’s competency and the procedure that is proposed for future releases. The form of the query is “Does subject hold competency C?”
- The subject is the person whose competence is being queried
- The competency C being queried is called the root competency
This page only describes the algorithms, and does not address security, privacy, or the interaction of the assertion processing and query/response mechanisms with external systems.
# Requirements
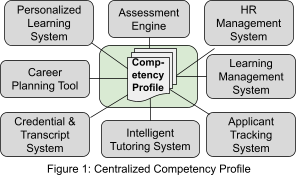
CaSS is designed to collect and provide information about a learner’s or employee’s competencies and skills to systems used in education, training, talent management, and workforce development. The simplest way to conceptualize the role of CaSS is as a “profile service” that collects, maintains, and publishes a list of the competencies that a learner or employee or job applicant has mastered (Figure 1). CaSS can operate in this mode, but this conceptualization fails to recognize the many real-world complexities and requirements surrounding the collection and determination of competencies. This section briefly discusses these as informative background.
# Competency Articulation via Relations
The first (and most obvious) requirement for sharing competency records among multiple systems is that they reference the same competencies or, barring that, have the ability to articulate different sets of competencies that address related skills, knowledge, and ability. The CaSS framework and competency services enable systems to reference common sets of competencies and enables relations to be defined among different competencies. However, it is impractical to expect that the systems using CaSS will be always be aware of the frameworks referenced by other such systems and, even if they are aware, that they will be able to use the relations in computations. It is therefore a requirement that CaSS be able to apply relations among competencies to competency data.
# Granularity and Roll-up Rules
The second requirement for sharing competency records stems from use cases in which the competency frameworks used by one system are at a completely different level of granularity than those used by another system. For example, intelligent tutoring systems such as Carnegie Learning’s cognitive tutors (opens new window) track highly granular “knowledge components,” competency-enabled learning management systems such as Moodle 3.1 (opens new window) assign competencies to activities and assessments, and systems used for staffing and career management are generally concerned with much less granular job and workforce skills. For a network such as that idealized in Figure 1 on the previous page to make sense, an intelligent tutoring system must be able to report data at the level of knowledge components while an applicant tracking system (ATS) consumes them at the level of job skills. The CaSS framework and competency services have the ability to store “roll-up rules” and relations that can be used to determine how knowledge about mastery of more granular competencies can be used as evidence of mastery of less granular competencies, but it is again unreasonable to expect that the ATS will know about the relevant relations and roll-up rules, much less know how to compute with them. Moreover, even if every collaborating system did retrieve and perform such computations, it is unlikely that they would do so in a consistent manner. It is therefore a requirement that CaSS be able to apply relations and roll-up rules to compute the state of a competency from the reported state of other related competencies, and that it do so in a documented, consistent, and potentially configurable manner.
# Confidence, Evidence, and Validity
The third requirement for sharing competency records comes from use cases in which:
- Multiple systems report data about an individual’s competency, which could be conflicting
- Users have a desire to know how much they can trust data in an individual’s profile
- Users want to examine evidence of competency, not just statements about competency
- Data is time limited, as often occurs with certifications or qualifications
All of these scenarios commonly arise in discussions about competencies with designers of education and training systems and proponents of competency-based approaches. It is therefore a requirement that CaSS be able to collect and report evidence, time limitations, and information on the confidence of an assertion about a learner’s competency. It is also a requirement that CaSS be able to resolve conflicting data in a documented, consistent, and potentially configurable manner.
Another phenomenon that is frequently mentioned and that is supported by cognitive science as well as real-world experience is that skills and knowledge can deteriorate or be lost over time unless they are practiced or reinforced. Although it is hard to find existing systems that take this into account when maintaining competency records, in designing CaSS it was considered a requirement that CaSS be able to associate decay functions with reported competencies.
# Assertions Rather than Records
Assessments can vary wildly with regard to reliability and validity (opens new window). In most cases, the reliability and validity of an assessment will not be known, and even in the case of assessments vetted by professional psychometricians, it is naive to treat assessment results as proving that an individual possesses a given competency. Moreover, claims of competency collected by CaSS may not even be based on an assessment, e.g. they could be derived from self-declarations or made under the assumption that a learner who has completed an activity has mastered the skills and knowledge addressed by that activity. For this reason, CaSS takes the generally accepted view that information about the competencies held by an individual consists of competency assertions. This is particularly important in high-stakes settings (opens new window), where making an unsupported claim that CaSS maintains an authoritative record of competencies could have undesirable consequences.
# Negative Assertions
Although traditional academic transcripts can include records of failing grades, the most commonly held view of a “competency profile” is that it lists the competencies that an individual holds and does not address the ones that are not held. Assertions, however, can be made to the effect that a test was not passed or that an individual failed to demonstrate a competency. Both SCORM (opens new window) and XAPI (opens new window) reporting mechanisms allow for this, as do many evaluation systems. It is therefore a requirement that CaSS receive and make both positive and negative assertions about an individual’s competencies.
This requirement is not without controversy. The ability to report that someone has demonstrate a lack of competency puts privacy and policies concerning the control of competency data in a new light. It is therefore a requirement that CaSS be configurable to at least not make negative assertions, regardless of whether it has collected any. It is also a requirement that CaSS take negative assertions into account when resolving conflicting data.
# Privacy and Security
The final major set of requirements concern privacy and security. Data about the competencies held by an individual can be highly sensitive data. Some basic considerations are:
- Many laws and regulations require that assessment data, grades, and other competency profile information be properly safeguarded and be divulged only on a need-to-know basis and for specific purposes.
- CaSS may operate in environments where portions of a learner’s competency profile are classified and non-public while other portions are unclassified and should be made available for the benefit of the learner. An example is a military profile where some skills and abilities are not shared with civilian organizations but where learners want other skills and abilities to be certified for future civilian employment and career management purposes.
- In some use cases the mere fact that an individual has been assessed on or attempted to acquire a competency may be considered sensitive information and protected by privacy policies, just as privacy policies protect the confidentiality of a user’s selection of reading materials (opens new window).
- In other use cases, information should be exchanged openly within a network of collaborating systems, and in still other use cases, data on learning outcomes and competencies must be made available to researchers without revealing the identity of the subjects (or any other PII).
More information is in the CaSS Privacy Manual. From an assertion processing perspective, it is a requirement that CaSS implement a robust and flexible security and privacy framework that supports a wide range of policies, use cases, and requirements.
# Definitions and Assumptions
The remainder of this document comprises the technical specifications for assertion processing in CaSS.
# Definitions and Notation
Assertion
An object with the properties defined in the Assertion schema (opens new window). The general form of an assertion is:
Agent A asserts at time T with validity through time V and with confidence p that subject S holds or does not hold competency C at level L based on associated evidence E
- p is a number in the closed interval [0,1]
- T and V are datetime objects
- E is a link to associated evidence
- C is identified via a URL that points to a CaSS competency
- A, S are CaSS identities
- p, E, L, T, and V are all optional.
The object model also supports an optional decay function, which is not used in the current release of CaSS.
Assertion Processor
A component of a CaSS service that answers queries from providers, collects the information needed to answer those queries, and applies an appropriate processing algorithm to compute the answers. It is assumed that an assertion processor can gather the information it requires and can formulate and transmit responses to queries using CaSS APIs.
Assertion Provider
A software application that can provide assertions. In this document, we assume that an assertion processor maintains a list of trusted assertion providers, which are referred to as the providers.
Identities
The public key portion of a CaSS identity. They securely and uniquely identify people, organizations, or software applications (see the CaSS Security Framework). An individual can have multiple identities in CaSS.
Processing Algorithm
An algorithm that (potentially) considers relations, roll-up rules, and data from collected assertions to determine whether or not an identity holds a given competency and (potentially) associates a confidence, evidence, and other data from the assertion information model with that determination.
Roll-up Rule
A rule that defines a computation that produces a mastery estimate for a given competency based on mastery estimates for other competencies, see the Roll-up Rule schema (opens new window).
Root Competency
When an assertion processor is queried about a competency, that competency becomes the root competency. The processor may use information about other competencies as well.
# Supported Relations
The following (and only the following) relations are currently supported by CaSS assertion processors:
- Broadens/Narrows - B narrows A if B is more specific than A. Broadens and narrows are inverse relationships, i.e. A broadens B and is more general than B if and only if B narrows A and is more specific than A.
- Requires - A requires B if A cannot be held without holding B. This is stronger than A broadens B in some models. The inverse is IsRequiredBy.
- Equivalent - A is equivalent to B if they can be treated as the same competency for the purpose of mastery. Note that if A and B are in different frameworks, it is possible that A is equivalent to B in A’s framework (e.g. the State of Oregon considers Utah’s competency as equivalent) but not in B’s framework (the state of Utah does not consider Oregon’s competency to be equivalent.).
# Assertion API
External systems query CaSS for information about an individual’s competency via the following API (opens new window):
# Query API
has = function(subject, competency, level, context, additionalSignatures, success, ask, failure)
subject- One or more identities that belong to an individual. (required).competency- The queried competency. (required)level- The queried level of the competency. (optional)context- The framework in which the competency is to be interpreted. (required)additionalSignatures- Additional, time limited, authorizations that can be granted for a single query. (Not currently used.)success- Callback method to retrieve the answer to a query when the query has been successfully processed.ask- If an assertion processor requires additional information, the “ask” parameter defines the method that the assertion processor should invoke to get this information. (optional)failure- The method to call if assertion processing fails.
# Storing Assertions
External systems store assertions [schema] (opens new window) in the CaSS repository using the CaSS Repository API.
# Current Assertion Processing Algorithm
# STEP 1
The first step is to create a processing graph G for the root competency. CaSS does this by starting with the root node R and retrieving all relations to other competencies. Each such relation defines an edge in the graph with nodes representing the two related competencies. If the same competency appears in two relations, it is represented twice by two different nodes. The edges are labelled with the relations (i.e. A requires B, A isRequiredBy B, A broadens B, A narrows B, or A is equivalent to B). This process is then repeated for each node in the graph, adding any relations that have not previously been retrieved and is iterated until no more relations can be found.
The result is a tree G with root R.
# STEP 2
The next steps involve determining the values of the nodes. In this scheme, a node (representing a competency) can have four values:
- T means that the competency is held
- F means that the competency is not held
- I means that the mastery status of the competency is indeterminate
- U means that the mastery status of the competency is unknown
The second step of the algorithm is to initialize all nodes with U.
# STEP 3
The algorithm retrieves all assertions for the leaves of G.
In this algorithm, all assertions are treated as T (the competency is held) or F (the competency is not held).
All roll-up roles for the leaf nodes are also computed using assertions retrieved for all target competencies in the roll-up rule. Each roll-up rule is considered to be an assertion, but have the values I or U in addition to T or F.
The value of a node is set to:
- U if all assertions are U or no assertions exist
- T if all assertions about that node are T or U
- F if all assertions about that node are F or U
- I otherwise
# STEP 4
The next step is to examine all parents of leaf nodes. In doing so, the values of each child of a node are considered assertions in the following way, where:
- P is the parent node
- C is the child node
Rules:
- If P broadens C, and C = F, then P is asserted to be F (holding P implies holding C)
- If P narrows C, and C = T, then P is asserted to be T (holding C implies holding P)
- If P requires C, and C = F, then P is asserted to be F
- If P is required by C, and C = T, then P is asserted to be T
- If P is equivalent to C, the value of C is asserted for P (T, F or I)
The values of all the parent nodes P are computed as in STEP 3 using direct assertions about the parent nodes, the assertions derived from all child nodes as above, and all roll-up rules. Equivalently, the leaf nodes are deleted, the assertions derived from them are retained, and STEP 3 is repeated.
Note
When a roll-up rule is applied to a node A, they only use direct assertions about the competencies in the rule. Roll-up rules can produce indeterminate or unknown results when data about the competencies in the rule are missing or conflicting. This behavior is determined by the definition of the rule.
# STEP 5
STEP 4 is repeated until the root node R is reached. The processing algorithm then returns the value of R.
# The Profile API
In addition to the Query API, CaSS implements a profile web service API that can be used to retrieve the type of learner profile depicted in Figure 1. This API is used by an external system to:
- Determine whether an individual represented by a user ID holds a given competency. The API will return T if the answer is “yes” (as determined by the assertion processor) and F otherwise.
- Retrieve a list of all competencies in a given framework held by an individual represented by a user ID.
- Set the value of a competency. When this is done, all previous values are overwritten.
This API can be invoked with processing turned on or off. When turned on, the assertion processor functions normally. When turned off, the value of a competency is determined only by the latests assertion made about that competency by an external system.
WARNING
This Profile API was developed to implement the classic notion of a profile that collaborating systems in a closed network can use to read and write the mastery stati of the a shared set of competencies. It purposely circumvents the CaSS security framework.
# Roll-up Rules
Roll-up rules in CaSS can currently be defined as nested AND's and OR's of a set of competencies. These are evaluated based on assertions about these competencies in the manner described in STEP 3 with the addition that a confidence threshold can be included. The syntax is shown in the following example:
(
[competency:A AND confidence:>0.6] AND
[competency:B AND confidence:>0.6]
) OR
[competency:C AND confidence:>0.9] OR
(
[competency:D] AND [competency:C]
)
Where A, B, C, and D are URLs to competencies managed by CaSS.
# Expected Changes
The following changes and modifications are anticipated for future releases:
- An assertion processor can keep a table of reputations that indicates how much it can rely on responses from each provider. A reputation is a number in the closed interval [0,1] with 0 meaning that the assertions from the provider are unreliable and 1 meaning the provider’s assertions are completely reliable. Best practices for determining or interpreting the value of a reputation are to be determined.
- Future implementations may include reputations for agents as well.
- Instead of creating duplicate nodes to create a tree, the processing graph will start out as a directed graph (A → B if A broadens or requires B) and cycles will be collapsed into equivalence classes represented by a single node. In this setup, each competency will be represented only once in the graph.
- The value of each node will be a real number in the closed interval [-1,1]. Negative numbers indicate the belief that an identity does not hold a competency. The value derived from an assertion will be the product of the confidence and ±1 (-1 for a negative assertion and +1 for a positive assertion), which may additionally be adjusted based on reputation.
- The graph will be processed depth first using a formula that weighs multiple assertions to derive a value.
- The associated API will be configurable to convert values of the root node to scales such as 1 - 4 or a discrete grading system. This mimics computations such as “grade point average” and is compatible with the way that certain learning management systems view competency assertions.
- We anticipate support for more sophisticated roll-up rules that can, for example, require that the sum of the confidences of multiple assertions exceed some threshold.